새로운 내용을 공부할 때
새로운 내용의 공부를 시작할 때 용어의 정의를 이해하지 못하거나 정확하게 알지 못한다면 그 용어가 포함된 문장을 이해하지 못합니다.
작은 단어 하나가 내용을 이해하지 못하게 하기 때문에 용어를 정확하게 이해하는 것이 중요합니다.
해시충돌 원인과 해결방법 학습
오늘은 해시 충돌이 발생하는 이유와 자바에서는 어떻게 해결했는지 학습했습니다.
오늘 학습 키워드
-
해시 함수(hashCode)
-
테이블(배열)
-
해시 충돌
-
Linear probing(선형 조사)
-
Quadratic probing(이차원 조사)
-
Double Hashing(이중 해싱)
-
LinkedList
-
Red-BlackTree
-
문자열풀
해시 관련
해시 함수란
자바에서 HashMap이나 HashSet의 내부 구현은 배열을 사용하여 구현했습니다.
배열을 사용하는 이유는 Hash 자료구조 특징인 중복을 허용하지 않습니다. 데이터를 추가할 때마다 중복 검사가 필요합니다.
만약 배열이 아닌 다른 방식으로 구현되었다면 탐색 시간 복잡도가 O(N)인 연결 리스트나 그나마 빠른 O(logN)도 데이터량이 많아진다면 느려집니다. 하지만 배열은 배열의 크기에 상관없이 찾으려는 데이터의 인덱스만 알면 접근 시간과 삽입 시간은 상수 시간 O(n)입니다.
만약 객체를 숫자로 변환하고 배열에 해당 정수 값을 인덱스로 사용하고 객체를 저장한다면 중복 검사나 데이터 조회가 상수 시간으로 가능해집니다. 이처럼 임의의 데이터를 정수로 변환하는 함수를 해시함수 라고 합니다.
자바에서는 Object 클래스 해시함수인 hashCode()를 메서드로 제공하고 있습니다. 재정의를 하지 않을 경우 기본 hashCode 결과는 객체의 메모리 주소이기 때문에 논리적으로 동일한 객체일지라도 다른 정수 값을 반환하기 때문에 해시 자료구조에 데이터를 저장하고 찾아오기 위해서는 재정의가 필요합니다.
해시 충돌이란
해시 충돌이란 해시 함수가 서로 다른 두 개의 입력값에 대해 동일한 출력값을 내는 상황을 말합니다. 이런 현상이 발생하는 이유는 무한한 입력값을 받아 유한한 출력값을 생성하는 경우, 즉 비둘기집 원리에 의해서 해시충돌은 항상 존재합니다.
위키백과
public int hashCode();
자바에서 해시 자료구조를 사용할 때 해시 충돌의 종류는 2가지 입니다.
hashCode()를 호출하여 다른 입력값이 같은 결과 값을 가질 때hash자료구조 내 배열안에 저장하기 위해 연산 결과가 같을 때
1번은 key1 != key2 이고 key1.hashCode() == key2.hashCode()인 경우를 말합니다.
2번은 key1 != key2이고 key1.hashCode() != key2.hashCode()인 상황에서도 해쉬 충돌이 발생하는 것을 말합니다.
2번이 발생하는 원인은 배열의 크기는 유한하며, 메모리를 사용하기 때문에 크기 확장에 한계가 있습니다.
만약 입력 값의 범위를 측정할 수 있어도 실제 환경에서 입력되는 수량에 맞춰 자료구조의 크기를 제한하기 때문입니다.
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length; // 현재 자료구조의 배열 길이를 구한다.
if ((p = tab[i = (n - 1) & hash]) == null) // 배열 크기에 맞게 해시 값을 & 연산한다.
tab[i] = newNode(hash, key, value, null);
}
hashMap에서 데이터를 저장할 때 hash 결과에 & 비트 연산을 하는 것을 확인할 수 있습니다.
int 범위에 비해 hashMap의 배열 크기가 작기 때문에 연산하는 과정에서 해시 값이 다르더라도 해시 충돌이 발생합니다.
HashMap 기본 사이즈 확인 방법
코드로 확인
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16리플렉션
public static void main(String[] args) throws NoSuchFieldException, IllegalAccessException { HashMap<String, String> map = new HashMap<>(); // 엔트리를 추가하여 내부 배열이 확장되도록 함 map.put("key1", "value1"); map.put("key2", "value2"); // HashMap의 클래스 객체를 가져옴 Class<?> hashMapClass = HashMap.class; // "table" 필드에 접근 Field tableField = hashMapClass.getDeclaredField("table"); tableField.setAccessible(true); // 내부 배열의 참조를 가져옴 Object[] table = (Object[]) tableField.get(map); // 배열의 크기를 출력 System.out.println("Internal array size: " + table.length); }자바 9 이상부터 모듈로 private에 접근하기 위해 옵션을 추가합니다.
--add-opens java.base/java.util=ALL-UNNAMED
해시 충돌 해결 방법
프로그래밍 언어 수준에서 해시 충돌을 해결할 수 없습니다. 해시 값이 동일할 경우 처리 방법이 나뉩니다.
Separate chaining(독립된 체이닝) 방식
이 방식은 해시 충돌 발생시 다른 버킷에 저장하는게 아니라 충돌된 객체를 자료구조로 저장하는 방식입니다.
-
Separate는 각 버킷을 독립된(separate) 자료 구조로 관리한다는 의미입니다.
-
Chaining은 각 버킷에서 충돌하는 요소들을 연결된 리스트 형태로 저장하는 것을 말합니다. 각
LinkedList의head를 가리키며, 충돌디 발생할 경우 새로운 요소를 맨 처음에 넣습니다.
왜? LinkedList를 사용할까?
- 해시 충돌이 많이 발생되지 않기 때문에 기본 배열 크기를 가진 배열 리스트보다 메모리를 효율적으로 사용합니다.
- 데이터 삽입이 헤더에 이루어지기 때문에 O(1) 시간에 가능하며, 최근에 추가된 데이터를 먼저 조회하는 경우 그리고 데이터 삭제/추가가 있는 경우 연결리스트가 효율적입니다.
- 배열리스트는 데이터 추가시 배열 복사가 발생하기 때문에 최적화가 되어도 연결리스트보다 삽입이 느려질 수 있습니다.
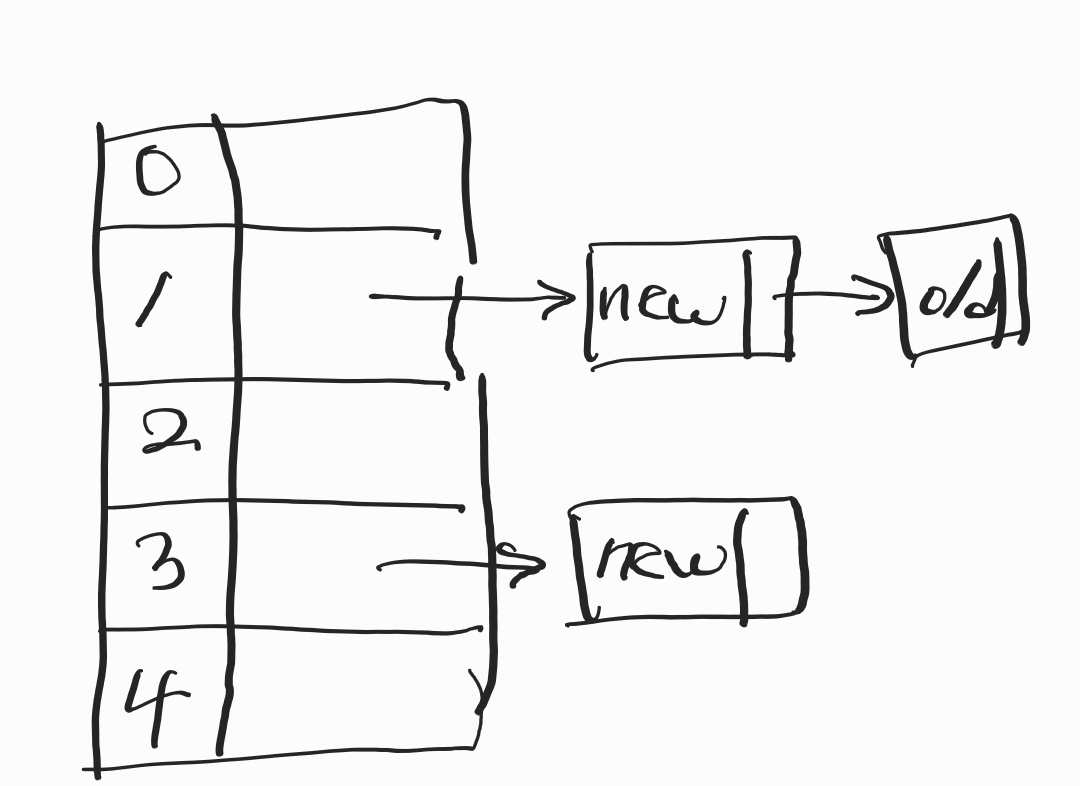
배열[i]로 접근하면 내부에 연결 리스트로 구현되어있습니다. 최신 데이터가 first에 추가됩니다.
Open addressing 방식
해시 충돌이 발생할 경우 다른 버킷을 탐사하여 빈 곳을 활용하는 방식입니다.
목표 레코드를 찾거나 사용되지 않는 배열 버킷을 찾을 때까지 계속 반복합니다. 프로빙 순서에 따라 나뉘어집니다.
선형 탐사(Linear Probing):
- 프로빙 간격이 고정된 경우 — 종종 1로 설정됩니다.
- 해시 충돌시 한칸씩 탐색하며 빈 공간에 저장합니다.
- 한쪽에 그룹화되어 군집현상(
클러스터링)이 발생할 수 있습니다. - 하나씩 증가하다 보니 해시 함수를 많이 실행하게 됩니다.
이차 탐사(Quadratic Probing):
- 프로빙 간격이 이차 함수로 증가하는 경우 (따라서 인덱스가 이차 함수로 설명됩니다).
- 이차탐사 = 해시함수 + 간격^2
hf_qp(key,i) = hf(key)+i^2- 해시 값이 같으면 충돌 횟수를 늘려도 이차탐사 결과는 동일하게 됩니다.
- 예를 들어, 해시함수 결과가 0이고 간격이 2라면 2, 4, 8, 10 … 으로 동일하게 순회됩니다.
이중 해싱(Double Hashing):
- 각 레코드에 대해 프로빙 간격이 고정되지만 다른 해시 함수에 의해 계산됩니다.
- 이중 해싱 = 해시함수 + 다른 해시함수 * 간격
- 이차 탐사의 한계인 동일 순회을 해결하였습니다.
- 단, 다른 해시함수는 map 배열의 사이즈와 서로소(
최대 공약수 1)여야 합니다. 그렇지 않으면 한번도 방문하지 않은 버킷이 발생합니다. - 배열의 크기가 10이고, 해시 함수가 2라면 방문 인덱스는 2i가 되기 때문에 10의 서로소인 1,3,7,9가 되어야합니다.
주의사항
Open addressing은 해시 함수 결과 위치에 값이 있을 경우 프로빙(탐사)를 합니다.
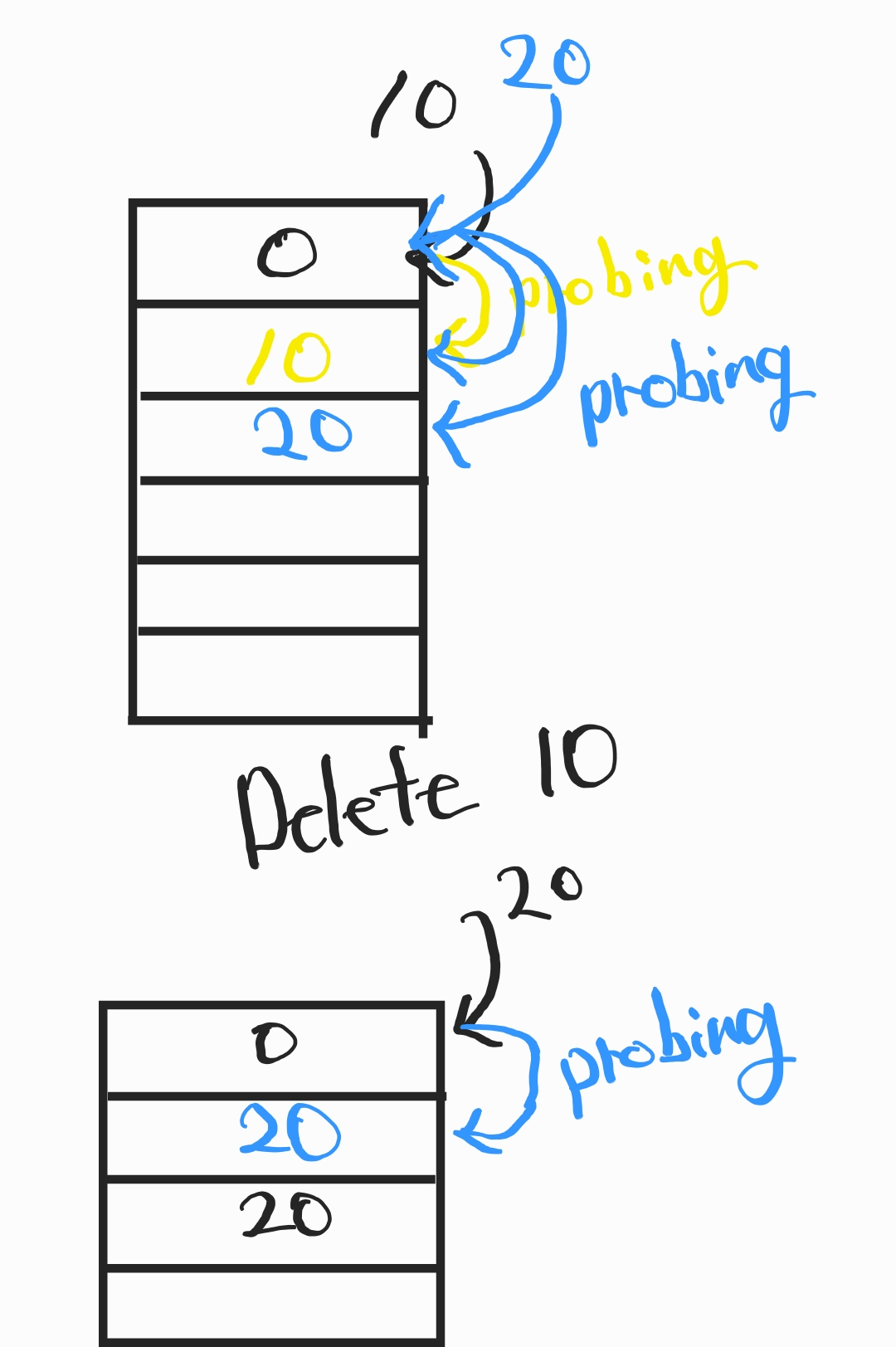
만약 10, 20, 30 의 해시 값이 모두 동일하여 탐사 후 빈 버킷에 저장되었습니다.
20의 존재를 확인하기 위해서 같은 해시 값을 가진 0, 10이 있어야 오픈 프로빙 방식을 통해 20까지 올 수 있습니다.
- 10을 삭제합니다.
- 20을 저장합니다.
- 해시 충돌로 빈 공간에 20을 저장하고 종료됩니다.
데이터 중복이 발생했습니다.
데이터 중복 해결방식
-
Delete Makring
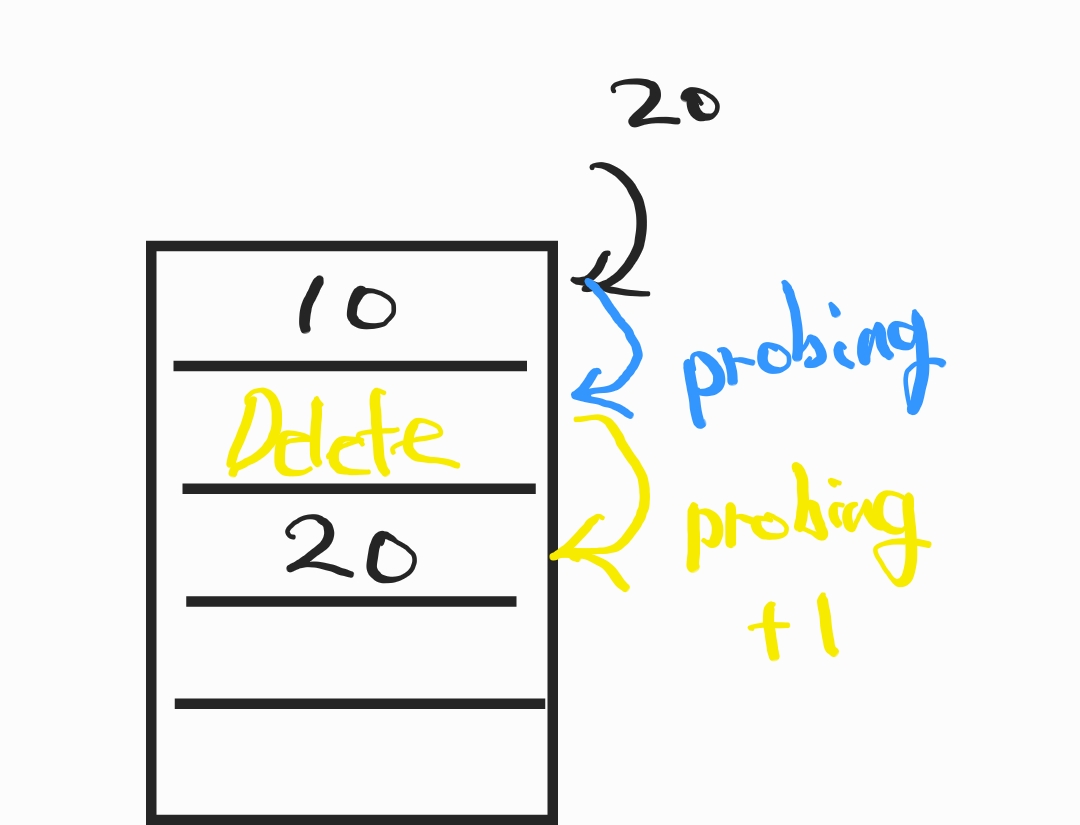
마킹 처리된 버킷이 있을 경우 다음 위치(Open Addressing) 를 확인하여 체크하는 방식입니다.
단점은 표시를 발견하면 무조건 다음 위치를 확인하기 때문에 데이터 삭제가 많다면 불필요한 탐색이 많아지게 됩니다.
-
데이터 삭제마다 (Open Addressing) key들을 모두 한 칸 앞으로 옮기는 방식
시간 복잡도 O(N) 발생
자바에서 해시 충돌 해결 방법
자바에서 해시 충돌을 해결하는 방법은 버전에 따라 다릅니다.
Java 7 이하
-
체이닝 방식
해시 충돌이 발생하면, 각 해시 버킷이 연결 리스트를 사용하여 동일한 해시 값을 가지는 객체를 저장합니다.
-
체이닝 한계
해시 충동이 많을 경우 연결 리스트가 길어지므로 탐색,삽입,삭제시 모든 노드를 순회하므로 성능 저하가 발생합니다.
Java 8 이상
-
개선된 체이닝
연결 리스트를 사용하던 기존 방식을 개선하여, 충돌이 발생하여 연결 리스트의 길이가 일정 길이(기본 8)이 넘으면, 해당 버킷을 트리화(
treeified)하여 성능을 개선합니다. -
이진 트리는 레드-블랙 트리를 사용하여 일정 높이를 유지합니다.
트리 구조의 정렬 기준은 뭘까?
트리 버킷으로 전환된 경우 주로 hashCode를 기준으로 정렬됩니다. 만약 동률인 경우 class C implements Comparable<C>인 두 요소는 compareTto메서드를 사용하여 정렬합니다.
트리 구조로 변환되는 기준
기본 연결 리스트 트리보다 레드-블랙 트리는 약 두 배의 크기를 가지기 때문에, 버킷에 충분한 노드가 있을 때만 변환됩니다.
또한, 트리 버킷은 일반적으로 잘 분포된 해시 코드에서는 거의 사용되지 않습니다.
문자열 풀
문자열 풀(Java String Pool) 은 JVM에 의해 String 타입이 저장되는 특수 메모리 영역을 말합니다.
JVM은 메모리를 효율적으로 운영하기 위해 문자열 풀을 사용합니다.
효율적으로 관리하는 방식은 동일한 값을 가진 리터럴 문자열과 클래스의 상수 문자열을 문자열 풀에 존재하는지 확인합니다. 만약 존재한다면 해당 문자열의 참조 값을 공유하게 됩니다.
public class StringTestV0 {
public static void main(String[] args) {
String str1 = "Hello, " + "world!";
String str2 = "Hello, ";
// 리터럴 문자열의 연산은 리터럴로 취급됩니다.
System.out.println("str1 == StringV1.HELLO_WORLD = " + (str1 == StringV1.HELLO_WORLD)); //true
System.out.println("str1 == StringV1.HELLO = " + (str2 == StringV1.HELLO)); //true
System.out.println("str2 == `Hello, ` = " + (str2 == "Hello, ")); //true
}
static class StringV1 {
public static final String HELLO_WORLD = "Hello, " + "world!";
public static final String HELLO = "Hello, ";
}
}
== 연산으로 확인할 수 있는 것은 문자열 리터럴을 할당한 변수는 동일한 참조 값을 가지게 됩니다.
System.out.println("str1 == `Hello, ` = " +
(System.identityHashCode(str2) == System.identityHashCode("Hello, "))); //true
실제 저장된 메모리 주소를 확인해도 같은 것을 확인할 수 있습니다.
힙 메모리와 메소드 영역
문자열 상수는 어디에 저장되는 것이 좋을까? 생각해봤습니다.
스택 영역은 메소드 호출이 종료되면 소멸되기 때문에 적합하지 않고, 모든 곳에서 참조가 가능한 영역은 힙 메모리와 메소드 영역입니다.
메소드 영역에 저장되는 애들은 클래스 정보(변수명, 메소드, 상위 클래스, 풀네임 등등..), static 변수, 메소드 등이 있습니다. 생각해보면 JVM이 생성하고 종료되기까지 메모리 위에 계속 남아있는 정보입니다. 만약 여기에 상수 풀이 있다면 사용하지 않은 문자열도 메모리 위에 계속 있을 겁니다.
동적으로 생성되고 소멸할 수 있는 힙 메모리에 저장되는 것이 효율적으로 문자열을 관리할 수 있고, GC 대상에 포함되어 불필요한 문자열도 제거할 수 있습니다.
버전 차이
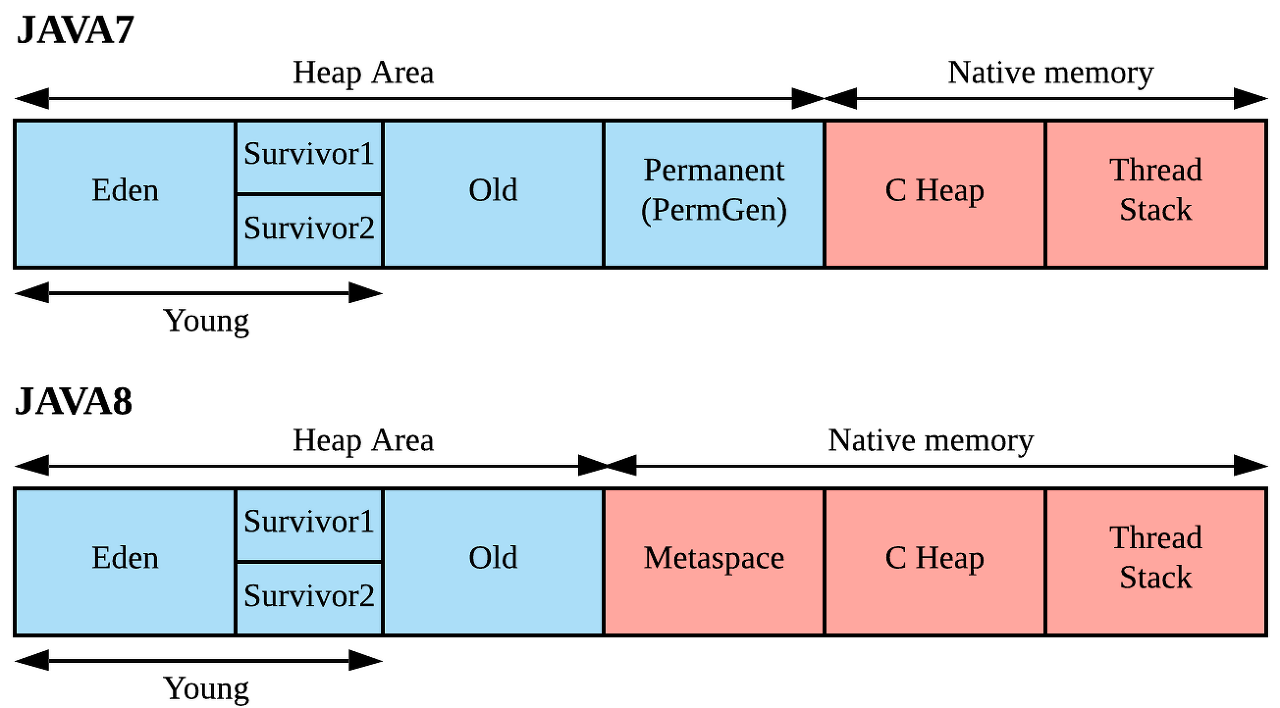
(이미지 출처: https://jaehoney.tistory.com/177)
JDK 8 부터 PermGen을 대체하여 Metaspace을 사용하게 됩니다.
PermGen는 클래스 메타데이터를 저장하며, 힙 메모리의 일부로 관리되었습니다. 고정 크리고 설정되었고 런타임시 확장시 불가했습니다. 동적으로 클래스 정보가 추가되거나 상수 풀이 커지게 될 경우 OOM이 발생하는 경우가 종종 있었습니다. 고정된 크기로 GC대상이 아니였습니다.
Metadata는 네이티브 메모리리를 사용하여 동적으로 확장될 수 있습니다. 기존 방식과 다르게 운영체제가 메모리를 할당하기 때문에 동적으로 확장할 수 있으며, 시스템의 가용 메모리에 따라 결정됩니다. GC 수행이 가능하며 OOM이 발생 위험이 감소합니다.
- 운영체제는 메모리 할당과 해제를 담당하고 JVM은 메모리 내부 자원 관리를 담당합니다.
문자열 풀에 저장되는 대상
String 자료형이라고 모두 문자열 풀에 저장되는 대상은 아닙니다. 리터럴 문자열은 문자열 풀의 저장 대상이지만
동적으로 변수끼리 연산하는 경우, new 생성자로 만드는 경우는 문자열 풀에 저장되지 않습니다.
public static void main(String[] args) {
String literalOperation = "Hello, " + "world!";
String literal = "Hello, world!";
String newString = new String("Hello, world!");
String hello = "Hello, ";
String world = "world!";
String varOperation = hello + world;
System.out.println("literalOperation == literal = " +
(literalOperation == literal)); // true
System.out.println("literalOperation == newString = " +
(literalOperation == newString)); // false
System.out.println("literalOperation == varOperation = " +
(literalOperation == varOperation)); // false
System.out.println("literal == newString = " +
(literal == newString)); // false
System.out.println("literal == varOperation = " +
(literal == varOperation)); // false
System.out.println("newString == varOperation = " +
(newString == varOperation)); // false
}
동일성 비교 == 는 변수에 저장된 값을 비교합니다. 참조 자료형일 경우 참조 값을 비교합니다.
- 리터럴 문자열끼리 연산은 동일한 참조 값를 가지고 있다는 것이 확인할 수 있습니다.
- 변수끼리 연산이나 생성자를 통해 만든
String타입은 서로 다른 주소 값을 가지는걸 확인할 수 있습니다.
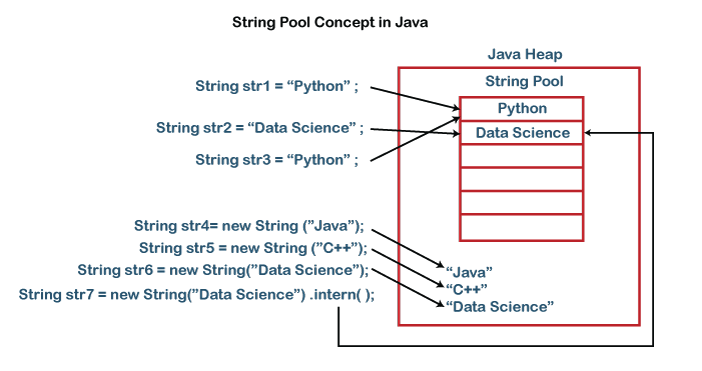
(이미지 출처 https://www.javatpoint.com/string-pool-in-java)
- 리터럴로 생성한 문자열은 힙 영역 내 문자열 풀에 저장됩니다.
String클래스 생성자 및 변수 연산자로 생성된 문자열은 문자열 풀을 제외한 영역에 저장됩니다.
STRING INTERNING
문자열 인터닝은 각각의 고유한 문자열 값의 복사본을 하나만 저장한 후에 재사용하는 방법입니다.
고유한 값은 String Pool영역에 HashMap테이블에 저장되며 각 문자열의 단일 사본을 intern(인턴)이라고 합니다.
문자열을 interning할때 equals(Obj)메서드로 동일한 문자열이 문자열 풀에 존재할 경우 문자열 풀의 문자열이 반환됩니다. 그렇지 않으면 String객체가 문자열 풀에 추가되고 String개체에 대한 참조가 반환됩니다.
시스템이 클래스를 로드하면 모든 클래스의 문자열 리터럴이 애플리케이션 수준 풀로 이동합니다.
런타임 시점에 문자열 결합이 된 경우는 새로운 객체로 힙 메모리에 생성됩니다. 따라서 문자열 결합이 많은 경우 StringBuilder를 사용하면 불필요한 개체 생성없이 효율적으로 처리할 수 있습니다.
intern 메소드 호출
intern()메서드
-
문자열 풀에 동일한 문자열이 있을 경우 풀에 있는 참조 값을 반환합니다.
-
해당 값을 가지는 문자열이 없는 경우 풀에 해당 값을 가지는 문자열 풀을 저장하고 참조를 반환합니다.
public static void main(String[] args) {
String newString = new String("Hello, world!");
String hello = "Hello, ";
String world = "world!";
String varOperation = hello + world;
// use intern()
String newInterned = newString.intern();
String varInterned = varOperation.intern();
// compare with identityHashCode
System.out.println("newString == `Hello, world!` = " +
(System.identityHashCode(newInterned) == System.identityHashCode("Hello, world!")));`
System.out.println("varInterned == `Hello, world!` = " +
(System.identityHashCode(varInterned) == System.identityHashCode("Hello, world!")));
}
두 결과는 모두 동일합니다.
newString == `Hello, world!` = true
varInterned == `Hello, world!` = true
문자열 풀 정리
문자열은 불변(immutable)객체입니다. 리터럴 문자열 연산은 컴파일 시점에 하나의 문자열로 관리되지만 변수와 연산하게 되는 경우 새로운 객체로 생성됩니다.
댓글남기기